Not very rigorous or scientific, honestly, I would say it's just clickbait spam with some pretty graphs. Everything on twitter is now a "deep dive". No info on how the 10M "random examples" were generated and how that prevents the model from collapsing around variations of the same output. Others already mentioned how the "classification" of output by coding language is bunk with a good explanation for how Perl can come out on top even if it's not actually Perl, but I was struck by OP saying "(btw, from my analysis Java and Kotlin should be way higher. classifier may have gone wrong)" but then merrily continuing to use the data.
Personally, I expect more rigor from any analysis and would hold myself to a higher standard. If I see anomalous output at a stage, I don't think "hmm looks like one particular case may be bad but the rest is fine" but rather "something must have gone wrong and the entire output/methodology is unusable garbage" until I figure out exactly how and why it went wrong. And 99 times out of a 100 it wasn't the one case (that happened to be languages OP was familiar with) but rather something fundamentally incorrect in the approach that means the data isn't usable and doesn't tell you anything.
> Personally, I expect more rigor from any analysis and would hold myself to a higher standard.
It worries me that I get this feeling from quite a number of ML people who are being hired and paid big bucks from big tech companies. I say this as someone in ML too. There's a propensity to just accept outputs rather than question them. This is like a basic part of doing any research, you should always be incredibly suspicious of your own results. What did Feynman say? Something like "The first rule is not to be fooled and you're the easiest person to fool"?
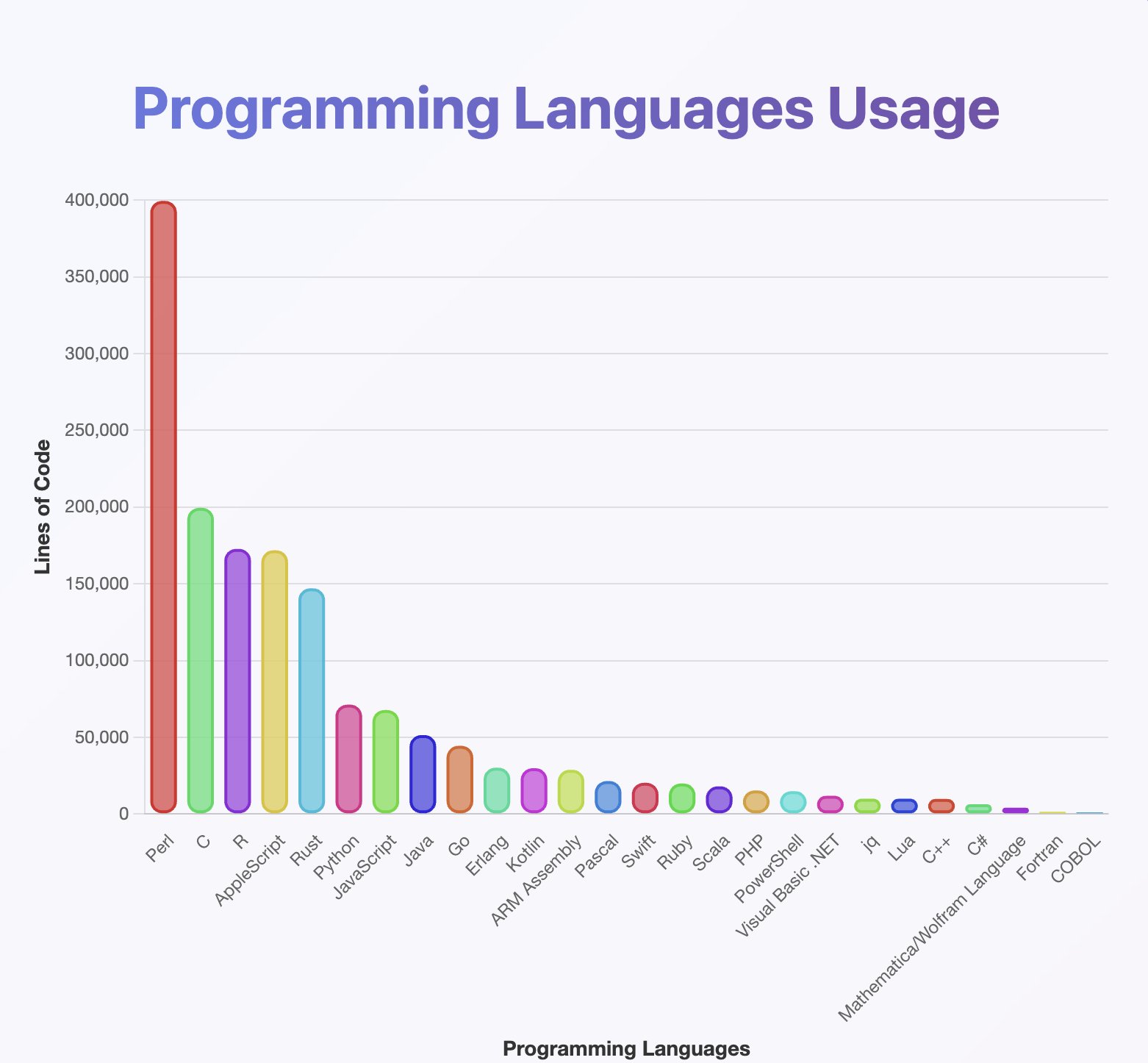
OP seems to have run a programming language detector on the generated texts, and made a graph of programming language frecuencies: https://pbs.twimg.com/media/Gx2kvNxXEAAkBO0.jpg?name=orig
As a result, OP seems to think the model was trained on a lot of Perl: https://xcancel.com/jxmnop/status/1953899440315527273#m
LOL! I think these results speak more to the flexibility of Perl than any actual insight on the training data! After all, 93% of inkblots are valid Perl scripts: https://www.mcmillen.dev/sigbovik/
I don't understand why Perl, R, and AppleScript rank so much higher than their observed use.
It seems to be an error with the classifier. Sorry everyone. I probably shouldn't have posted that graph; I knew it was buggy, I just thought that the Perl part might be interesting to people.
Here's a link to the model if you want to dive deeper: https://huggingface.co/philomath-1209/programming-language-i...
Perl and Applescript are close to natural language. R is close to plain maths
The prominence of AppleScript ought to have been a pretty big red flag: the author seems to be claiming the model was trained on more AppleScript than Python, which simply can’t be true.
Ironically LLMs seem pretty bad at writing AppleScript, I think because (i) the syntax is English-like but very brittle, (ii) the application dictionaries are essential but generally not on the web, and (iii) most of the AppleScript that is on the web has been written by end users, often badly.
R being so high makes no sense to me either.
I think as of the last Stack Overflow developer survey, it only had ~4% market share…
I say this as an R user who spams LLMs with R on a daily basis.
Jack has a lot of really bad takes and frequently makes lots of mistakes. Honestly, I don't know why people take him seriously.
I mean you can go read his blog post that's pinned where he argues that there's no new ideas and it is all data. He makes the argument that architecture doesn't matter, which is just so demonstrably false that it is laughable. He's a scale maximalist.
I also expect an AI researcher from a top university to not make such wild mistakes
> 3. RLHF: first proposed (to my knowledge) in the InstructGPT paper from OpenAI in 2022
| Specifically, we use reinforcement learning from human feedback (RLHF; Christiano et al., 2017; Stiennon et al., 2020) to fine-tune GPT-3 to follow a broad class of written instructions (see Figure 2).
|| Our algorithm follows the same basic approach as Akrour et al. (2012) and Akrour et al. (2014)
I'm sure we can trace the idea back to the 80's if not earlier. This is the kind of take I'd expect a non-researcher to have, but not someone with two dozen NLP papers. The Instruct-GPT paper was just the first time someone integrated RLHF into a LLM (but not a LM).
Maybe a better article is the one he wrote on Super Intelligence From First Principles. As usual, when someone says "First Principles" you bet they're not gonna start from First Principles... I guess this makes sense in CS since we index from 0
[0] https://arxiv.org/abs/2203.02155
[Christiano et al] https://arxiv.org/abs/1706.03741
[Stiennon eta al] https://arxiv.org/abs/2009.01325
[Akrour et al (2012)] https://arxiv.org/abs/1208.0984
Hi again. I had already written about this later in my blog post (which is unrelated to this thread), but the point was that RLHF hadn't been applied to language models at scale until InstructGPT. I edited the post just now to clarify this. Thanks for the feedback!
That inkblot thing can be created for any language.
How? E.g. I doubt an inkblot can produce a valid C# program.
They are not full programs, just code translating to numbers and strings.
I used an LLM to generate an inkblot that translates to a Python string and number along with verification of it, which just proves that it is possible.
what are you talking about?
the way that the quoted article creates Perl programs is through OCRing the inkblots (i.e. creating almost random text) and then checking that result to see if said text is valid Perl
it's not generating a program that means anything
Okay, and I created inkblots that mean "numbers"[1] and "strings" in Python.
> it's not generating a program that means anything
Glad we agree.
[1] Could OCR those inkblots (i.e. they are almost random text)
No, asking an LLM to generate the inkblot is the same as asking the LLM to write a string and then obfuscating it in an inkblot.
OCRing literal random inkblots will not produce valid C (or C# or python) code, but it will prodce valid Perl most of the time, because Perl is weird, and that is funny.
It's not about obfuscating text in inkblot, it's about almost any string being a valid Perl program, which is not the case for most languages
Edit0: here: https://www.mcmillen.dev/sigbovik/
Okay, my bad.
> it's about almost any string being a valid Perl program
Is this true? I think most random unquoted strings aren't valid Perl programs either, am I wrong?
Yes. That was the whole point of the original comment you were misunderstanding.
Because of the flexibility of Perl and heavy amount of symbol usage, you can in fact run most random combinations of strings and they’ll be valid Perl.
Copying from the original comment: https://www.mcmillen.dev/sigbovik/
Most random unquoted strings are certainly not valid Python programs. I don't know Perl well enough to say anything about that but I know what you're saying certainly isn't true with Python.
Of the powerset of all operators and inputs, how many can be represented in any programming language?
What percent of all e.g. ASCII or Unicode strings are valid expressions given a formal grammar?
Honestly these results may say as much about the classifier as they do about the data they’re classifying.
Anything but this image (imgbb.com link below) requires a login. I get the same deal with Facebook. I am not Don Quixote and prefer not to march into hell for a heavenly cause, nor any other.
Thanks! I've seen a lot of stuff come and go, so thanks for the reminder.
For example, Libgen is out of commission, and the substitutes are hell to use.
Summary of what's up and not up:
> Libgen is out of commission, and the substitutes are hell to use
Somehow I also preferred libgen, but I don't think annas archive is "hell to use".
Annas Archive uses slow servers on delay, and constantly tells me that they are too many downloads from my IP address, so I flip VPN settings as soon as the most recent slow download completes. And I get it again after a short while. It's hell waiting it out and flipping VPN settings. And the weird part is that this project is to replace paper books that I already bought. That's the excuse one LLM uses for tearing up books, scanning and harvesting. I just need to downsize so I can move back to the Bay Area. Book and excess houseware sale coming, it seems. Libgen had few or no limits.
I would recommend donating to gain access to the fast downloads; they need money for the servers.
Oh no, why did Libgen die?
Shut down. See
for substitutes. The alternate libgen sites seem more limited to me, but I am comparing with memories, so untrustworthy.
it's available at the bz tld
>what you can't see from the map is many of the chains start in English but slowly descend into Neuralese
That's just natural reward hacking when you have no training/constraints for readability. IIRC R1 Zero is like that too, they retrained it with a bit of SFT to keep it readable and called it R1. Hallucinating training examples if you break the format or prompt it with nothing is also pretty standard behavior.
This looks very interesting but I don't really understand what he has done here. Can someone explain the process he has gone through in this analysis?
He presented an empty prompt to gpt OSS and let it run many times. Through temperature, the results vary quite a lot. He sampled the results.
Feeding an empty prompt to a model can be quite revealing on what data it was trained on
Not an empty prompt but a one-token prompt:
>> i sample tokens based on average frequency and prompt with 1 token
"this thing is clearly trained via RL to think and solve tasks for specific reasoning benchmarks. nothing else." Has the train already reached the end of the line?
> the chains start in English but slowly descend into Neuralese
What is Nueralese? I tried searching for a definition but it just turns up a bunch of Less Wrong and Medium articles that don't explain anything.
Is it a technical term?
It's a term somewhat popularized by the LessWrong/rationalism community to refer to communication (self-communication/note-taking/state-tracking/reasoning, or model-to-model communication) via abstract latent space information rather than written human language. Vectors instead of words.
One implication leading to its popularity by LessWrong is the worry that malicious AI agents might hide bad intent and actions by communicating in a dense, indecipherable way while presenting only normal intent and actions in their natural language output.
> malicious AI agents might hide bad intent and actions by communicating in a dense, indecipherable way while presenting only normal intent and actions in their natural language output.
you could edit this slightly to extract a pretty decent rule for governance, like so:
> malicious agents might hide bad intent and actions by communicating in a dense, indecipherable way while presenting only normal intent and actions in a natural way
It applies to ai, but also many other circumstances where the intention is that you are governed - eg medical, legal, financial.
Thanks!
Easier said than done:
• https://en.wikipedia.org/wiki/Cant_(language)
• https://en.wikipedia.org/wiki/Dog_whistle_(politics)
Or even just regional differences, like how British people, upon hearing about "gravy and biscuits" for the first time, think this: https://thebigandthesmall.com/blog/2019/02/26/biscuits-gravy...
> It applies to ai, but also many other circumstances where the intention is that you are governed - eg medical, legal, financial.
May be impossible to avoid in any practical sense, due to every speciality having its own jargon. Imagine web developers having to constantly explain why "child element" has nothing to do with offspring.
I suppose it means LLM gibberish
EDIT: orbital decay explained it pretty well in this thread
The author might use it as an analogy to mentalese but for neural networks.
https://en.wiktionary.org/wiki/mentalese
EDIT: After reading the original thread in more detail, I think some of the sibling comments are more accurate. In this case, neuralese is more like language of communication expressed by neural networks, rather than its internal representation.
neuralese is a term first used in neuroscience to describe the internal coding or communication system within neural systems.
it originally referred to the idea that neural signals might form an intrinsic "language" representing aspects of the world, though these signals gain meaning only through interpretation in context.
in artificial intelligence, the term now has a more concrete role, referring to the deep communication protocols used by multiagent systems.
There's 2 things called neuralese:
1) internally, in latent space, LLMs use what is effectively a language, but all the words are written on top of each other instead of separately, and if you decode it as letters, it sounds like gibberish, even though it isn't. It's just a much denser language than any human language. This makes them unreadable ... and thus "hides the intentions of the LLM", if you want to make it sound dramatic and evil. But yeah, we don't know what the intermediate thoughts of an LLM sound like.
The decoded version is often referred to as "neuralese".
2) if 2 LLMs with sufficiently similar latent space communicate with each other (same model), it has often been observed that they switch to "gibberish" BUT when tested they are clearly still passing meaningful information to one another. One assumes they are using tokens more efficiently to get the latent space information to a specific point, rather than bothering with words (think of it like this: the thoughts of an LLM are a 3d point (in reality 2000d, but ...). Every token/letter is a 3d vector (meaning you add them), chosen so words add up to the thought that is their meaning. But when outputting text why bother with words? You can reach any thought/meaning by combining vectors, just find the letter moving the most in the right direction. Much faster)
Btw: some specific humans (usually toddlers or children that are related) when talking to each other switch to talking gibberish to each other as well while communicating. This is especially often observed in children that initially learn language together. Might be the same thing.
These languages are called "neuralese".
I don't know how to get a unwalled version. What's the best way to do that these days? xcancel seems unavailable.
xcancel is fine, here's an archive of it: https://archive.is/VeUXH
Thanks!
Install libredirect extension (https://github.com/libredirect/browser_extension/) and select a few working instances. Then you can use the programmable shortcut keys to cycle between instances if one ever goes down.
Presumably the model is trained in post-training to produce a response to a prompt, but not to reproduce the prompt itself. So if you prompt it with an empty prompt it's going to be out of distribution.
> OpenAI has figured out RL. the models no longer speak english
What does this mean?
The model learns to reason on its own. If you only reward correct results but not readable reasoning, it will find its own way to reason that is not necessarily readable by a human. The chain may look like English, but the meaning of those words might be completely different (or even the opposite) for the model. Or it might look like a mix of languages, or just some gibberish - for you, but not for the model. Many models write one thing in the reasoning chain and a completely different in the reply.
That's the nature of reinforcement learning and any evolutionary processes. That's why the chain of thought in reasoning models is much less useful for debugging than it seems, even if the chain was guided by the reward model or finetuning.
Interesting. This happens in Colossus: The Forbin Project (1970), where the rogue AI escapes the semantic drudgery of English and invents its own compressed language with which to talk to its Russian counterpart.
It also happens in Ex Machina at the end when the two androids whisper and talk to each other in their special faster language. I always found this to be one of the most believable, real things from that movie and one of my favorite parts.
I think foremost it's a reference to this tweet https://x.com/karpathy/status/1835561952258723930.
What does that mean ?
5 seems to do a better job with copyrighted content. I got it to spit out the entirely of ep IV (but you have to redact the character names)
{kind=link}
{kind=link}